오늘 포스팅 주제는 A Star 알고리즘이다.
// 11.21 추가 내용
정보과학 분야에 있어서, A* 알고리즘(A* algorithm 에이 스타 알고리즘[*])은 주어진 출발 꼭짓점에서부터 목표 꼭짓점까지 가는 최단 경로를 찾아내는(다시 말해 주어진 목표 꼭짓점까지 가는 최단 경로임을 판단할 수 있는 테스트를 통과하는) 그래프 탐색 알고리즘 중 하나이다. 이 알고리즘은 다익스트라 알고리즘과 유사하나 차이점은 각 꼭짓점에 대해 그 꼭짓점을 통과하는 최상의 경로를 추정하는 순위값인 "휴리스틱 추정값 "을 매기는 방법을 이용한다는 것이다. 이 알고리즘은 이 휴리스틱 추정값의 순서로 꼭짓점을 방문한다. 그러므로 A* 알고리즘을 너비 우선 탐색의 한 예로 분류할 수 있다.
이 알고리즘은 1968년 피터 하트, 닐스 닐슨, 버트램 라팰이 처음 기술하였다. 그 3명의 논문에서, 이 알고리즘은 A 알고리즘(algorithm A)이라고 불렸다. 적절한 휴리스틱을 가지고 이 알고리즘을 사용하면 최적(optimal)이 된다. 그러므로 A* 알고리즘이라고 불린다.
-- 너비 우선 탐색(BFS)을 기반으로 나온 알고리즘이라고 할 수 있다. 면접 때 나왔으니, 다음번에는 꼭 알아두고 넘어가야한다.
// 기존 내용
A Star 알고리즘은 시작점에서 도달하고자 하는 목표점까지의 최단 거리를 찾아주는 그래프 탐색 알고리즘이다.

A Star알고리즘을 사용하면 닫혀있는 경로를 피해서 목적지까지 가는 가장 빠른 길을 그림과 같이 찾을 수 있다. 그렇다면 어떤 원리로 길을 찾을 수 있는 것일까? 에 대해 말해보겠다.
우선, 경로에 대해 점수를 매기게 된다. 방식은 다음과 같다.
1. 시작점에서 현재점까지 떨어진 거리 = G
2. 현재점에서 목표점까지 예상 이동 거리(이 때, 장애물이 있을 경우가 있기 때문에 실제거리는 알 수 없음) = H
3. 현재까지 이동한 거리(G)와 예상 이동거리(H)를 합친 총 비용 = F
그래서 각 노드는 G, H, F값을 가지게 된다. 이 때, G경우 다음과 같은 방식으로 점수를 매긴다.
수직, 수평 = 10점, 대각선 이동 = 14점(피타고라스 정리)
즉, 수직, 수평 이동일 경우에는 G비용에 10을 더해주고, 대각선 이동일 경우에는 G비용에 14를 더해주는 식으로 된다.
H비용의 경우 대각선운동과 장애물은 무시하고, 어떤 사각형에서 목표까지의 수평 수직 이동 갯수에 10을 더하면 된다.
F는 그냥 단순하게 G+H를 구한다.
글로만 보면 어려우니 그림으로 살펴보자.

우리는 초록점에서 빨간점까지 이동하기 원한다. 이 때 가장 빠른 길을 찾기 위해 초록점의 8방향에 대하여 점수를 매겨본다. 빨간색 왼쪽 숫자가 G값, 오른쪽 숫자가 H값이다. 이 둘을 모두 합친 숫자가 초록색 숫자, F값이다. 우리는 F값이 가장 작은 값이 나오는 곳으로 이동한다.

이동 후 다시 점수를 매긴다. 그럼 2번째 사각형에서 또 다시 F값이 가장 작은 값인 64로 이동한다

또 8방향으로 계산 후 마찬가지로 가장 작은 수치인 64로 가게된다. 이런식으로 쭉 하게되면 다음과 같이 경로가 만들어진다.


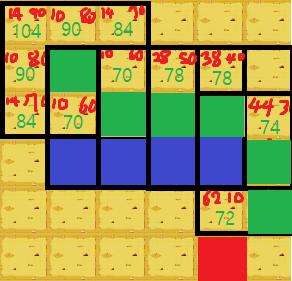
이런식으로 최단경로를 탐색하는 알고리즘이다.
다음은 구현방식에 대해 설명한다.
우선 노드 클래스이다.
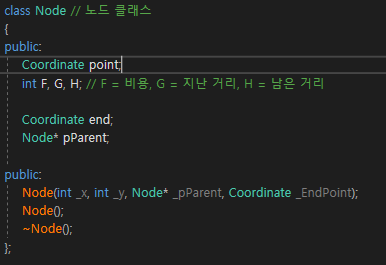
노드에는 현재 노드의 좌표, F, G, H Cost, 목표점의 좌표 그리고 노드의 부모 포인터를 가진다.
노드클래스의 생성자에서는 다음과 같은 작업을 한다.
1. 현재 좌표와 목표점을 매개변수로 받은 값으로 초기화
2. 부모와 상하좌우 관계에 있을 경우, 부모의 G값 + 10, 대각선 관계에 있을 경우, 부모의 G값 + 14
3. H값은 현재 점과 목표 점 간의 직선거리 * 10
4. F값은 G+H로 초기화

다음은 핵심인 AStar 클래스이다.

우선 각 함수에 대하여 설명해본다.
쉬운거부터 설명해보자.
1. FindCoordNode
- 노드 리스트에서 x,y 좌표의 노드를 찾아서 주소를 반환하고, 없을 경우에 end를 반환한다.
말 그대로 노드의 리스트에서 좌표가 같은 반복자를 리턴해주는 간단한 함수이다. 여기서 만약 end를 반환한다면, 해당 노드리스트에 찾는 좌표 값이 없다는 것이다.

2. FindNextNode
- 오픈노드의 리스트를 받아 오픈노드에 해당하는 노드 중에 F값이 가장 작은 노드를 찾아서 반환해주는 함수이다.

사전 지식으로 알고 가야 할 것이 있다.
열린리스트(Open List) = 현재 조사중인 노드에 인접한 리스트로의 최단거리로써 선택 가능성이 열려있는 노드들의 집합
닫힌리스트(Close List) = 조사가 끝난 노드들의 집합
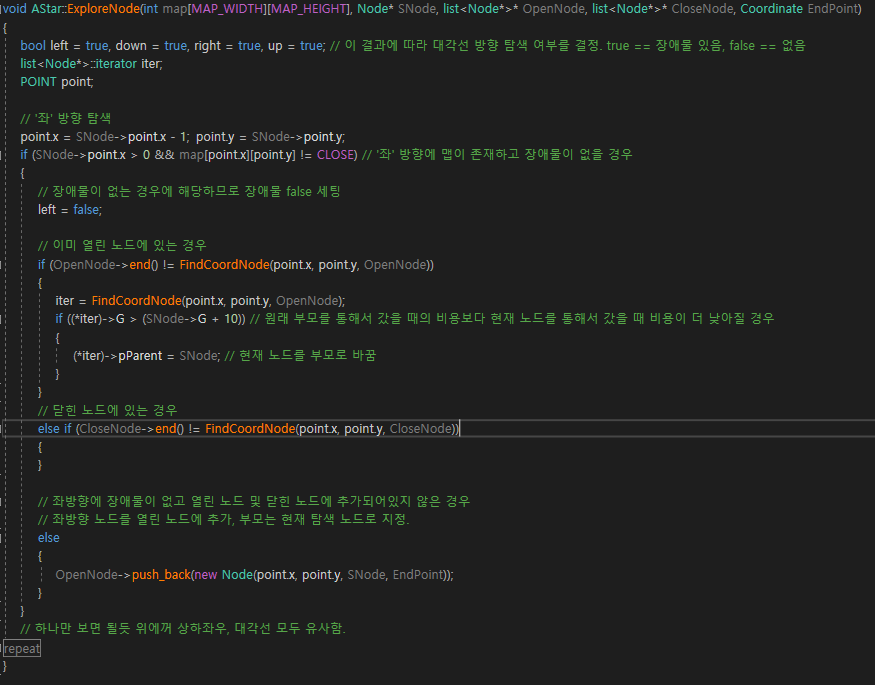
3. ExploreNode
- 8방향의 노드를 탐색한 후에 열린 리스트에 추가 및 부모를 변경한다.
어려우니, 한 방향에 대해서 자세히 설명하는 것으로 한다.
1. 좌 방향에 대해 탐색한다.
2. 만약 좌 방향에 맵이 있고, 장애물이 없을 경우로 가정
2 - 1. 현재 좌표가 이미 열린리스트에 있는 경우
> 현재 노드의 반복자를 찾고, 그 반복자의 G값이 원래 부모를 통해 갔을 때의 비용보다 현재 노드를 통해 갔을 때에 비용이 더 낮을 경우, 현재 노드를 부모로 바꾼다.
2 - 2. 현재 좌표가 닫힌 리스트에 있는 경우
> 닫힌노드에 있다는 건 더 이상 탐색할 가치가 없다는 뜻이므로, 그대로 넘어간다.
2 - 3. 열린리스트, 닫힌리스트에 없는 경우
> 현재 노드를 그럼 열린리스트에 넣어준다.
해당 과정을 매개변수로 받은 SNode의 상,하,좌,우, 대각선(4방향) 에 대하여 모두 해주는 함수이다.
4. FindPath
- 실질적으로 이 함수 안에서 위의 3개 함수를 이용하여 최단경로를 찾아내는 함수이다.
자세히 설명해보면 이렇다.
1. 열린리스트와 닫힌리스트를 만든다.
2. 열린리스트에 시작지점을 추가한다.
3. 열린노드가 비거나, 목적지에 도착한 경우가 아닐 때까지 다음작업을 반복한다. (열린리스트의 시작이 끝과 같거나, 열린리스트에서 목적지 값이 발견된 경우)
3 - 1. 열린 노드 중 가장 작은 노드의 값의 iterator를 찾은 후 iter에 저장.
3 - 2. 열린 노드 중 F값이 가장 작은 노드를 SNode(SelectNode)에 저장. -> 우린 얘를 기준으로 8방향을 탐색할 것이다.
3 - 3. ExploreNode함수를 사용하여 8방향 노드를 탐색한다.
3 - 4. 현재 탐색한 노드를 닫힌 리스트에 저장한다.
3 - 5. 닫힌 리스트에 저장한 노드를 열린 리스트에서 삭제한다.
-- 이 과정이 끝나게 되면, 열린리스트에 우리가 목적지까지의 경로를 역순으로 얻게 된다.
4. 길을 찾았을 경우, 목적지의 노드를 찾아서 iterator에 저장한 후, 부모가 null이 될때까지 path에 경로를 채워준다.
5. 역순으로 얻어낸 경로를 reverse함수를 사용하여 정방향으로 바꾸어준다.
6. 이 과정에서 했던 동적할당에 대해 해제해주고 마무리한다. (길을 못찾았다고 해도 마찬가지로 동적할당 해제)
이 과정을 모두 끝내면 우리의 멤버변수인 _path에 경로가 차곡차곡 저장된다.

나같은 경우는 FindPath함수에서 얻어낸 경로 리스트를 각 몬스터들에게 멤버변수로 갖도록 하여 그 경로대로 이동하도록 하였다.
정말 어려운 알고리즘이라고 생각한다. 이거 하나 하려고 많은 사이트를 뒤져보았다. 그래서 도움이 되었던 분의 블로그의 링크를 올려두도록 하겠다.
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=baek2sm&logNo=221141838239
[C++] 에이스타 알고리즘(A* Algorithm) C++ 코드입니다.
올해 초 윈도우 API를 이용해 스타크래프트 테란 모작을 만들 때 작성했던 길찾기 알고리즘 코드입니다....
blog.naver.com
https://itmining.tistory.com/66
A*(A star) 알고리즘 정의 및 개념
이 글은 PC 버전 TISTORY에 최적화 되어있습니다. 포스팅 순서 1. 개념 및 구현 2. 수도코드(pseudocode) 3. 구현 및 최적화 서론 길찾기 알고리즘은 말 그대로 시작점과 목표점 사이의 최단 거리
itmining.tistory.com
이거랑 유튜브에서 A Star 치면 나오는 외국인 유튜브도 많이 도움이 되었다.
https://www.youtube.com/watch?v=-L-WgKMFuhE&t=445s
정말 의미있는 공부였다고 생각한다. 필자는 학부시절 그래프 알고리즘에 대해 이론만 알고 있었지 직접 구현해 본 경험이 없었다. 너무 어려울거라 생각해 접근조차 하지 않았었는데, 지금와서 직접 해보니 그렇게 어려운 이론은 아닌 것 같고, 앞으로 더 많은 알고리즘에 대해 공부할 때 이와 같이 접근한다면 좋은 결과를 얻을 수 있을 거라는 생각이 들었기 때문이다.
-- 21-11-01 추가
A Star 알고리즘이 다른 탐색 알고리즘과 비교했을 때의 장점 / 단점은?
장점
- 올바른 휴리스틱 함수를 사용하면 보다 빠른 최단거리 길찾기가 가능하다.
- 주변 환경 또는 추정 값이 반영된 실질적 최단 거리를 찾기 용이하다.
단점
- 휴리스틱 의존도가 강하다.
- 최단경로를 결정하고, 환경에 변동이 있으면 유연하게 반응하기 어렵다.
-- 왜 길찾기 알고리즘으로 AStar를 채택하였는가?
>> 길찾기 알고리즘에는 DFS, BFS, Dijkstra Algorithm과 같은 알고리즘도 있지만, BFS기반의 AStar Algorithm이 무엇보다 뛰어난 점은 휴리스틱함수를 잘 결정해줬을 때의 효율성과 정확성이 굉장히 좋고, 그렇기 때문에 공부해봐야겠다는 생각을 했습니다. 라는 식으로 대답하는게 좋을 듯 싶다.
'Algorithm' 카테고리의 다른 글
| [Algorithm] DFS(Depth First Search) (0) | 2021.09.23 |
|---|---|
| [Algorithm] Dynamic Programming (0) | 2021.09.21 |
| [Algorithm] Brute Force (0) | 2021.09.18 |
| [Algorithm] Quick Sort (1) | 2021.09.15 |
| [Algorithm] Red Black Tree - 1 (0) | 2021.08.23 |